In a data warehouse however, the dimension data is generally de-normalized to reduce the number of joins required to query the data.
Often, a data warehouse is organized as a star schema, in which a fact table is directly related to the dimension tables, as shown in this example:
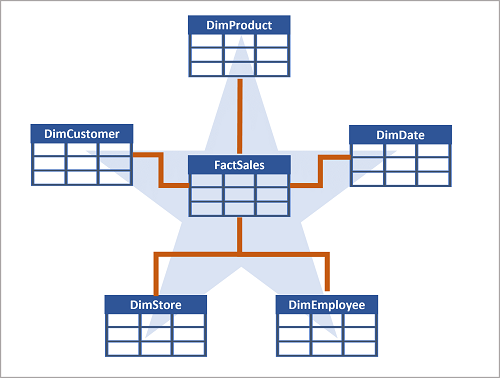 ]
]
when an entity has a large number of hierarchical attribute levels, or when some attributes can be shared by multiple dimensions (for example, both customers and stores have a geographical address), it can make sense to apply some normalization to the dimension tables and create a snowflake schema, as shown in the following example:

Create Data Ware House Table:
First create dedicated SQL pool
When provisioning a dedicated SQL pool, you can specify the following configuration settings:
- A unique name for the dedicated SQL pool.
- A performance level for the SQL pool, which can range from DW100c to DW30000c and which determines the cost per hour for the pool when it's running.
- Whether to start with an empty pool or restore an existing database from a backup.
- The collation of the SQL pool, which determines sort order and string comparison rules for the database. (You can't change the collation after creation).
Types of Table we do create in DWH:
- Fact tables
- Dimension tables
- Staging tables
If we have to create small or medium size dataset we can preferred Azure SQL, but for large data set we can implement Data Ware house in Azure Synapse Analytics instead of SQL Server.
It's important to understand some key differences when creating tables in Synapse Analytics:
Data Integrity Constraints: Dedicated SQL pools in Synapse Analytics don't support foreign key and unique constraints as found in other relational database systems like SQL Server.
Indexes: Synapse Analytics dedicated SQL pools support clustered indexes as found in SQL Server, the default index type is clustered columnstore.
**Some tables may include data types that can't be included in a clustered columnstore index (for example, VARBINARY(MAX)), in which case a clustered index can be used instead.
- Hash: A deterministic hash value is calculated for the specified column and used to assign the row to a compute node.
- Round-robin: Rows are distributed evenly across all compute nodes.
- Replicated: A copy of the table is stored on each compute node.
| Table type | Recommended distribution option |
|---|
| Dimension | Use replicated distribution for smaller tables to avoid data shuffling when joining to distributed fact tables. If tables are too large to store on each compute node, use hash distribution. |
| Fact | Use hash distribution with clustered columnstore index to distribute fact tables across compute nodes. |
| Staging | Use round-robin distribution for staging tables to evenly distribute data across compute nodes. |
Creating Dimension Table:
1.
CREATE TABLE dbo.DimGeography
(
GeographyKey INT IDENTITY NOT NULL,
GeographyAlternateKey NVARCHAR(10) NULL,
StreetAddress NVARCHAR(100),
City NVARCHAR(20),
PostalCode NVARCHAR(10),
CountryRegion NVARCHAR(20)
)
WITH
(
DISTRIBUTION = REPLICATE,
CLUSTERED COLUMNSTORE INDEX
);
2.
CREATE TABLE dbo.DimCustomer
(
CustomerKey INT IDENTITY NOT NULL,
CustomerAlternateKey NVARCHAR(15) NULL,
GeographyKey INT NULL,
CustomerName NVARCHAR(80) NOT NULL,
EmailAddress NVARCHAR(50) NULL,
Phone NVARCHAR(25) NULL
)
WITH
(
DISTRIBUTION = REPLICATE,
CLUSTERED COLUMNSTORE INDEX
);
3.
CREATE TABLE dbo.DimDate
(
DateKey INT NOT NULL,
DateAltKey DATETIME NOT NULL,
DayOfMonth INT NOT NULL,
DayOfWeek INT NOT NULL,
DayName NVARCHAR(15) NOT NULL,
MonthOfYear INT NOT NULL,
MonthName NVARCHAR(15) NOT NULL,
CalendarQuarter INT NOT NULL,
CalendarYear INT NOT NULL,
FiscalQuarter INT NOT NULL,
FiscalYear INT NOT NULL
)
WITH
(
DISTRIBUTION = REPLICATE,
CLUSTERED COLUMNSTORE INDEX
);
Creating Fact Table:
CREATE TABLE dbo.FactSales
(
OrderDateKey INT NOT NULL,
CustomerKey INT NOT NULL,
ProductKey INT NOT NULL,
StoreKey INT NOT NULL,
OrderNumber NVARCHAR(10) NOT NULL,
OrderLineItem INT NOT NULL,
OrderQuantity SMALLINT NOT NULL,
UnitPrice DECIMAL NOT NULL,
Discount DECIMAL NOT NULL,
Tax DECIMAL NOT NULL,
SalesAmount DECIMAL NOT NULL
)
WITH
(
DISTRIBUTION = HASH(OrderNumber),
CLUSTERED COLUMNSTORE INDEX
);
Creating Staging Tables:
CREATE TABLE dbo.StageProduct
(
ProductID NVARCHAR(10) NOT NULL,
ProductName NVARCHAR(200) NOT NULL,
ProductCategory NVARCHAR(200) NOT NULL,
Color NVARCHAR(10),
Size NVARCHAR(10),
ListPrice DECIMAL NOT NULL,
Discontinued BIT NOT NULL
)
WITH
(
DISTRIBUTION = ROUND_ROBIN,
CLUSTERED COLUMNSTORE INDEX
);
Using External Tables:
CREATE EXTERNAL DATA SOURCE StagedFiles
WITH (
LOCATION = 'https://mydatalake.blob.core.windows.net/data/stagedfiles/'
);
GO
CREATE EXTERNAL FILE FORMAT ParquetFormat
WITH (
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
);
GO
CREATE EXTERNAL TABLE dbo.ExternalStageProduct
(
ProductID NVARCHAR(10) NOT NULL,
ProductName NVARCHAR(200) NOT NULL,
ProductCategory NVARCHAR(200) NOT NULL,
Color NVARCHAR(10),
Size NVARCHAR(10),
ListPrice DECIMAL NOT NULL,
Discontinued BIT NOT NULL
)
WITH
(
DATA_SOURCE = StagedFiles,
LOCATION = 'products/*.parquet',
FILE_FORMAT = ParquetFormat
);
GO
Load Data Ware house Table:
COPY INTO dbo.StageProducts
(ProductID, ProductName, ProductCategory, Color, Size, ListPrice, Discontinued)
FROM 'https://mydatalake.blob.core.windows.net/data/stagedfiles/products
Designing Data Ware house Load Process:
Usually data loading is performed as a periodic batch process in which inserts and updates to the data warehouse are coordinated to occur at a regular interval (for example, daily, weekly, or monthly).
In most cases, you should implement a data warehouse load process that performs tasks in the following order:
- Ingest the new data to be loaded into a data lake, applying pre-load cleansing or transformations as required.
- Load the data from files into staging tables in the relational data warehouse.
- Load the dimension tables from the dimension data in the staging tables, updating existing rows or inserting new rows and generating surrogate key values as necessary.
- Load the fact tables from the fact data in the staging tables, looking up the appropriate surrogate keys for related dimensions.
- Perform post-load optimization by updating indexes and table distribution statistics.
Datawarehouse Query:
Aggregating Measure by Dimension Attribute:
SELECT dates.CalendarYear,
dates.CalendarQuarter,
SUM(sales.SalesAmount) AS TotalSales
FROM dbo.FactSales AS sales
JOIN dbo.DimDate AS dates ON sales.OrderDateKey = dates.DateKey
GROUP BY dates.CalendarYear, dates.CalendarQuarter
ORDER BY dates.CalendarYear, dates.CalendarQuarter;
Join in Snow flake schema:
SELECT cat.ProductCategory,
SUM(sales.OrderQuantity) AS ItemsSold
FROM dbo.FactSales AS sales
JOIN dbo.DimProduct AS prod ON sales.ProductKey = prod.ProductKey
JOIN dbo.DimCategory AS cat ON prod.CategoryKey = cat.CategoryKey
GROUP BY cat.ProductCategory
ORDER BY cat.ProductCategory;
Using Rank Function:
SELECT ProductCategory,
ProductName,
ListPrice,
ROW_NUMBER() OVER
(PARTITION BY ProductCategory ORDER BY ListPrice DESC) AS RowNumber,
RANK() OVER
(PARTITION BY ProductCategory ORDER BY ListPrice DESC) AS Rank,
DENSE_RANK() OVER
(PARTITION BY ProductCategory ORDER BY ListPrice DESC) AS DenseRank,
NTILE(4) OVER
(PARTITION BY ProductCategory ORDER BY ListPrice DESC) AS Quartile
FROM dbo.DimProduct
ORDER BY ProductCategory;
Retrieving an approximate Count:
SELECT dates.CalendarYear AS CalendarYear,
COUNT(DISTINCT sales.OrderNumber) AS Orders
FROM FactSales AS sales
JOIN DimDate AS dates ON sales.OrderDateKey = dates.DateKey
GROUP BY dates.CalendarYear
ORDER BY CalendarYear;
Load Dimension Table:
After loading data into staging table, We can load data into dimension Table.
Method 1:
Using Create table:
CREATE TABLE dbo.DimProduct
WITH
(
DISTRIBUTION = REPLICATE,
CLUSTERED COLUMNSTORE INDEX
)
AS
SELECT ROW_NUMBER() OVER(ORDER BY ProdID) AS ProdKey,
ProdID as ProdAltKey,
ProductName,
ProductCategory,
Color,
Size,
ListPrice,
Discontinued
FROM dbo.StageProduct;
We can combine existing data and new data using Create Table:
CREATE TABLE dbo.DimProductUpsert
WITH
(
DISTRIBUTION = REPLICATE,
CLUSTERED COLUMNSTORE INDEX
)
AS
SELECT stg.ProductID AS ProductBusinessKey,
stg.ProductName,
stg.ProductCategory,
stg.Color,
stg.Size,
stg.ListPrice,
stg.Discontinued
FROM dbo.StageProduct AS stg
UNION ALL
SELECT dim.ProductBusinessKey,
dim.ProductName,
dim.ProductCategory,
dim.Color,
dim.Size,
dim.ListPrice,
dim.Discontinued
FROM dbo.DimProduct AS dim
WHERE NOT EXISTS
( SELECT *
FROM dbo.StageProduct AS stg
WHERE stg.ProductId = dim.ProductBusinessKey
);
Rename Table:
RENAME OBJECT dbo.DimProduct TO DimProductArchive;
RENAME OBJECT dbo.DimProductUpsert TO DimProduct;
Using Insert Statement:
INSERT INTO dbo.DimCustomer
SELECT CustomerNo AS CustAltKey,
CustomerName,
EmailAddress,
Phone,
StreetAddress,
City,
PostalCode,
CountryRegion
FROM dbo.StageCustomers
Load Time Dimension Table:
Time dimension tables store a record for each time interval based on the grain by which you want to aggregate data over time.
Load Slowly Change Dimension:
Types of Slow Change Dimension:
Type 0: Type 0 dimension data can't be changed. Any attempted changes fail.
Type 1: In type 1 dimensions, the dimension record is updated in-place. Changes made to an existing dimension row apply to all previously loaded facts related to the dimension.
Type 2: In a type 2 dimension, a change to a dimension results in a new dimension row. Existing rows for previous versions of the dimension are retained for historical fact analysis and the new row is applied to future fact table entries.
| CustomerKey | CustomerAltKey | Name | Address | City | DateFrom | DateTo | IsCurrent |
|---|
| 1211 | jo@contoso.com | Jo Smith | 999 Main St | Seattle | 20190101 | 20230105 | False |
| 2996 | jo@contoso.com | Jo Smith | 1234 9th Ave | Boston | 20230106 | | True |
Implement Type 1 and Type 2
Method 1:
Add new Customer:
INSERT INTO dbo.DimCustomer
SELECT stg.*
FROM dbo.StageCustomers AS stg
WHERE NOT EXISTS
(SELECT * FROM dbo.DimCustomer AS dim
WHERE dim.CustomerAltKey = stg.CustNo)
Type 1 Update
UPDATE dbo.DimCustomer
SET CustomerName = stg.CustomerName
FROM dbo.StageCustomers AS stg
WHERE dbo.DimCustomer.CustomerAltKey = stg.CustomerNo;
Type 2 Update
INSERT INTO dbo.DimCustomer
SELECT stg.*
FROM dbo.StageCustomers AS stg
JOIN dbo.DimCustomer AS dim
ON stg.CustNo = dim.CustomerAltKey
AND stg.StreetAddress <> dim.StreetAddress;
Method 2:
MERGE dbo.DimProduct AS tgt
USING (SELECT * FROM dbo.StageProducts) AS src
ON src.ProductID = tgt.ProductBusinessKey
WHEN MATCHED THEN
UPDATE SET
tgt.ProductName = src.ProductName,
tgt.ProductCategory = src.ProductCategory,
tgt.Color = src.Color,
tgt.Size = src.Size,
tgt.ListPrice = src.ListPrice,
tgt.Discontinued = src.Discontinued
WHEN NOT MATCHED THEN
INSERT VALUES
(src.ProductID,
src.ProductName,
src.ProductCategory,
src.Color,
src.Size,
src.ListPrice,
src.Discontinued);
Load Fact Table:
Typically, a regular data warehouse load operation loads fact tables after dimension tables. This approach ensures that the dimensions to which the facts will be related are already present in the data warehouse.
The staged fact data usually includes the business (alternate) keys for the related dimensions, so your logic to load the data must look up the corresponding surrogate keys. When the data warehouse slowly changing dimensions, the appropriate version of the dimension record must be identified to ensure the correct surrogate key is used to match the event recorded in the fact table with the state of the dimension at the time the fact occurred.
Query to Load fact Table:
INSERT INTO dbo.FactSales
SELECT (SELECT MAX(DateKey)
FROM dbo.DimDate
WHERE FullDateAlternateKey = stg.OrderDate) AS OrderDateKey,
(SELECT MAX(CustomerKey)
FROM dbo.DimCustomer
WHERE CustomerAlternateKey = stg.CustNo) AS CustomerKey,
(SELECT MAX(ProductKey)
FROM dbo.DimProduct
WHERE ProductAlternateKey = stg.ProductID) AS ProductKey,
(SELECT MAX(StoreKey)
FROM dbo.DimStore
WHERE StoreAlternateKey = stg.StoreID) AS StoreKey,
OrderNumber,
OrderLineItem,
OrderQuantity,
UnitPrice,
Discount,
Tax,
SalesAmount
FROM dbo.StageSales AS stg
Post Load Optimiztion
After loading new data into the data warehouse, it's a good idea to rebuild the table indexes and update statistics on commonly queried columns.
Rebuild Index:
ALTER INDEX ALL ON dbo.DimProduct REBUILD
Update statistics:
CREATE STATISTICS productcategory_stats
ON dbo.DimProduct(ProductCategory);
Manage Workload in Azure Synapse Analytics: Azure Synapse Analytics allows you to create, control and manage resource availability when workloads are competing. This allows you to manage the relative importance of each workload when waiting for available resources.
To facilitate faster load times, you can create a workload classifier for the load user with the “importance” set to above_normal or High.
Dedicated SQL pool workload management in Azure Synapse consists of three high-level concepts:
- Workload Classification
- Workload Importance
- Workload Isolation