Azure Databricks is a cloud-based distributed platform for
data processing built on Apache Spark. Databricks was designed to unify data
science, data engineering, and business data analytics on Spark.
Azure Databricks is hosted on the Microsoft Azure cloud
platform, and integrated with Azure services such as Azure Active Directory,
Azure Storage, Azure Synapse Analytics, and Azure Machine Learning.
The
Azure Databricks workspace provides a unified interface and tools for most data
tasks, including:
·
Data processing
workflows scheduling and management
·
Working in SQL
·
Generating dashboards
and visualizations
·
Data ingestion
·
Managing security,
governance, and HA/DR
·
Data discovery,
annotation, and exploration
·
Compute management
·
Machine learning (ML)
modeling and tracking
·
ML model serving
·
Source control with
Git
Azure
Databricks is optimized for three specific types of data workload and
associated user personas:
·
Data Science and
Engineering
·
Machine Learning
·
SQL*
In
addition to the workspace UI, you can interact with Azure Databricks
programmatically with the following tools:
·
REST API
·
CLI
·
Terraform
·
SQL Warehouses are only available in premium Azure
Databricks workspaces.

Apache Spark clusters - Spark is a distributed data processing solution that
makes use of clusters to scale processing across multiple compute nodes. Each Spark cluster has a driver node to coordinate processing jobs, and one or more worker nodes on which the processing occurs.
Databricks File System (DBFS) - While each cluster node has its own local file system
(on which operating system and other node-specific files are stored), the nodes
in a cluster have access to a shared, distributed file system in which they can
access and operate on data files. The Databricks File System (DBFS) enables you to mount cloud storage and use it to
work with and persist file-based data.
Notebooks - One of the most common ways for data analysts, data
scientists, data engineers, and developers to work with Spark is to write code
in notebooks.
Hive metastore - Hive is an open source technology used to define a
relational abstraction layer of tables over file-based data. The tables can
then be queried using SQL syntax. The table definitions and details of the file
system locations on which they're based is stored in the metastore for a Spark
cluster.
Delta Lake - Delta Lake builds on the relational table schema abstraction over
files in the data lake to add support for SQL semantics commonly found in
relational database systems. Capabilities provided by Delta Lake include
transaction logging, data type constraints, and the ability to incorporate
streaming data into a relational table. SQL Warehouses - SQL Warehouses are relational compute resources with endpoints that
enable client applications to connect to an Azure Databricks workspace and use
SQL to work with data in tables. The results of SQL queries can be used to
create data visualizations and dashboards to support business analytics and
decision making. SQL Warehouses are only available in premium tier Azure Databricks workspaces.
Read file using spark:
df1 = spark.read.format("csv").option("header", "true").load("dbfs:/FileStore/shared_uploads/user@outlook.com/products_1_.csv")
display(df1)
save it as table
df1.write.saveAsTable("products")
%sql
SELECT
ProductName, ListPrice
FROM
products
WHERE Category = 'Touring Bikes';
Azure Databricks service launches and manages Apache Spark clusters within your Azure subscription. Apache Spark clusters are groups of computers that are treated as a single computer and handle the execution of commands issued from notebooks.
In Databricks, the notebook interface is typically the driver program. This driver program contains the main loop for the program and creates distributed datasets on the cluster, then applies operations to those datasets. Driver programs access Apache Spark through a SparkSession object regardless of deployment location.
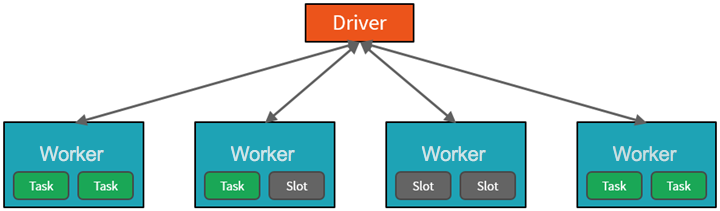
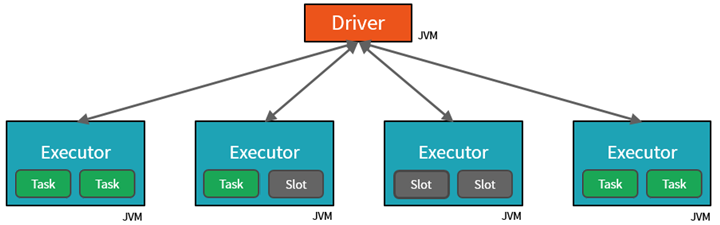
Spark parallelizes jobs at two levels:
- The first level of parallelization is the executor - a Java virtual machine (JVM) running on a worker node, typically, one instance per node.
- The second level of parallelization is the slot - the number of which is determined by the number of cores and CPUs of each node.
- Each executor has multiple slots to which parallelized tasks can be assigned
- .
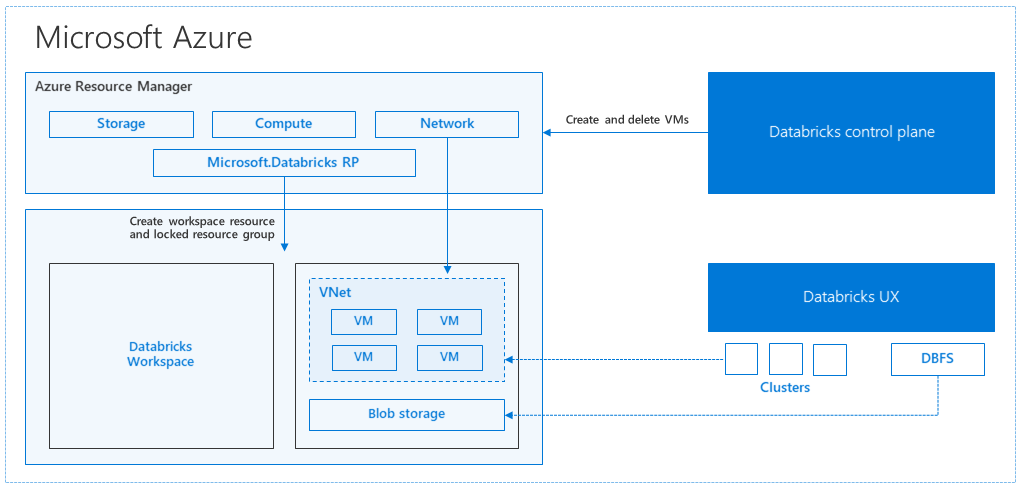
How Azure manages cluster resources
When you create an Azure Databricks workspace, a Databricks appliance is deployed as an Azure resource in your subscription. When you create a cluster in the workspace, you specify the types and sizes of the virtual machines (VMs) to use for both the driver and worker nodes, and some other configuration options, but Azure Databricks manages all other aspects of the cluster.
All metadata for your cluster, such as scheduled jobs, is stored in an Azure Database with geo-replication for fault tolerance.
Internally, Azure Kubernetes Service (AKS) is used to run the Azure Databricks control-plane and data-planes via containers running on the latest generation of Azure hardware (Dv3 VMs), with NvMe SSDs capable of blazing 100us latency on high-performance Azure virtual machines with accelerated networking.
After the services within your managed resource group are ready, you can manage the Databricks cluster through the Azure Databricks UI and through features such as auto-scaling and auto-termination.
Use Spark in notebooks
You can run many different kinds of application on Spark, including code in Python or Scala scripts, Java code compiled as a Java Archive (JAR), and others. Spark is commonly used in two kinds of workload:
- Batch or stream processing jobs to ingest, clean, and transform data - often running as part of an automated pipeline.
- Interactive analytics sessions to explore, analyze, and visualize data.
Exploring data with dataframes
load the data into a dataframe and display the first 10 rows:
pyspark
df = spark.read.load('/data/products.csv',
format='csv',
header=True
)
display(df.limit(10))Specifying a dataframe schema
Using SQL expressions in Spark
The Dataframe API is part of a Spark library named Spark SQL, which enables data analysts to use SQL expressions to query and manipulate data.
Creating database objects in the Spark catalog
Using the Spark SQL API to query data
Visualize data
Using graphics packages in code
Get Started with Delta Lake
Creating a Delta Lake table from a dataframe
versionAsOf option:timestampAsOf option:Create and query catalog tables
So far we've considered Delta Lake table instances created from dataframes and modified through the Delta Lake API. You can also define Delta Lake tables as catalog tables in the Hive metastore for your Spark cluster, and work with them using SQL.
Tables in a Spark catalog, including Delta Lake tables, can be managed or external;
- A managed table is defined without a specified location, and the data files are stored within the storage used by the metastore. Dropping the table not only removes its metadata from the catalog, but also deletes the folder in which its data files are stored.
- An external table is defined for a custom file location, where the data for the table is stored. The metadata for the table is defined in the Spark catalog. Dropping the table deletes the metadata from the catalog, but doesn't affect the data files.
CREATE TABLE IF NOT EXISTS statement or the CREATE OR REPLACE TABLE
Create empty table with schema:
%sql
CREATE TABLE ManagedSalesOrders( Orderid INT NOT NULL, OrderDate TIMESTAMP NOT NULL, CustomerName STRING, SalesTotal FLOAT NOT NULL)USING DELTA
Create table using delta table builder pi:
from delta.tables import *
DeltaTable.create(spark) \ .tableName("default.ManagedProducts") \ .addColumn("Productid", "INT") \ .addColumn("ProductName", "STRING") \ .addColumn("Category", "STRING") \ .addColumn("Price", "FLOAT") \ .execute()
Fetch data from table:
%sql
SELECT orderid, salestotalFROM ManagedSalesOrders
Use delta lake for streaming the data:
Spark includes native support for streaming data through Spark Structured Streaming, an API that is based on a boundless dataframe in which streaming data is captured for processing. A Spark Structured Streaming dataframe can read data from many different kinds of streaming source, including network ports, real time message brokering services such as Azure Event Hubs or Kafka, or file system locations.
Streaming with delta lake:
You can use a Delta Lake table as a source or a sink for Spark Structured Streaming. For example, you could capture a stream of real time data from an IoT device and write the stream directly to a Delta Lake table as a sink - enabling you to query the table to see the latest streamed data. Or, you could read a Delta Table as a streaming source, enabling you to constantly report new data as it is added to the table.
Using a Delta Lake table as a streaming source
A stream is created that reads data from the Delta Lake table folder as new data is appended
from pyspark.sql.types import *Using a Delta Lake table as a streaming sink
stop method of the streaming query:SQL Ware house with data bricks:
Dashboards
Dashboards enable you to display the results of queries, either as tables of data or as graphical visualizations.
you can schedule the dashboard to refresh is data periodically, and notify subscribers by email that new data is available.